검색 초능력자 되게 해주는 벡터DB✨ 님, 안녕하세요? 서두석 프로예요🙋. 오늘은 슈퍼히어로 영화 ‘어벤져스:인피니티 워’ 이야기로 시작하려 해요. 영화에서는 우주 최강 빌런 타노스에 맞서기 위해 역대급 슈퍼히어로들이 한자리에 모이지만, 해결책이 쉽게 떠오르지 않는 난관에 봉착해요. 이를 해결한 사람이 있었으니, 명상에 잠겨 있던 닥터 스트레인지인데요. 사실 그는 타임스톤을 사용하여 1,400만 개 이상의 미래 시나리오를 검토한 결과, 타노스를 이기는 방법을 찾아낸 거였죠.😎 |
|
|
타임스톤이 미래의 가능성을 탐색하는데 사용된 것과 유사하게, 본격적인 AI 시대에 들어서며 대량의 데이터를 효율적으로 관리하고 분석하여 우리가 직면하는 문제를 해결하는 데 큰 도움이 되는 기술이 주목받고 있어요. 바로 '벡터 데이터베이스(Vector Database)'라는 기술인데요. 그럼 지금부터 벡터 데이터베이스에 대해 자세히 알아볼까요? |
|
|
• 검색 초능력자 되게 해주는 벡터DB✨
• 벡터DB가 떠오르는 이유
• 벡터DB의 강력한 파워는 어느 정도?
• 벡터DB 최신 솔루션은?💡
• 이미 우리 손엔 타임스톤 하나씩? |
|
|
지금 우리에겐 닥터 스트레인지가 가진 타임스톤⌚은 없지만, 보다 나은 의사결정을 위해 하루에도 수없이 사용하고 있는 방법이 있어요. 그.것.은. 바로! ‘검색’이죠😅 특히나 요즘은 기존의 텍스트 검색을 넘어, 원하는 결과값을 보다 수월히 얻을 수 있도록 음성, 이미지 등 여러 방식으로 검색할 수 있게 되었는데요. 이처럼 여러 차원의 지식 베이스를 참조하기 위해서는 텍스트 및 음성, 영상과 같은 다양한 형태의 (비정형) 데이터를 빠르게 저장하고 검색 할 수 있도록 하는 기술이 필요해요. 그게 벡터DB인 거죠. |
|
|
벡터DB는 각 문서를 벡터 공간 상에 표현하고, 두 점 사이의 거리를 구하는 방법 중의 하나인 유클리드 거리 등의 메트릭을 이용하여 검색어와 가장 가까운 문서부터 순서대로 보여주는데요. 이렇게 함으로써 사용자가 원하는 정보를 더 빠르고 정확하게 찾을 수 있답니다. |
|
|
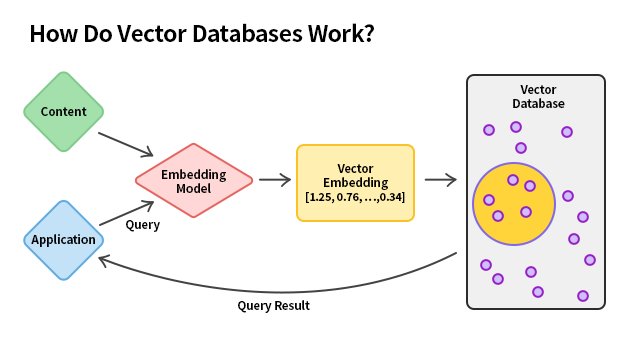
✅ 콘텐트(Content) : 이미지, 텍스트, 비디오 등 비정형 데이터가 입력된다. 이 데이터는 다양한 형태로 존재하지만, 그 자체로는 기계가 이해하기 어렵기 때문에 벡터로 변환하는 과정이 필요하다.
✅ 애플리케이션(Application) : 사용자가 질문이나 검색을 애플리케이션을 통해 입력한다. 이 애플리케이션은 사용자 입력을 받아서 벡터 데이터베이스에 쿼리(query)를 요청한다.
✅ 임베딩 모델(Embedding Model) : 입력된 데이터를 수치화하여 벡터 형식으로 변환하고, 이 벡터는 각각의 데이터가 의미하는 바를 숫자로 표현한다.
✅ 벡터 임베딩(Vector Embedding) : 데이터를 벡터로 변환한 결과를 나타낸다. 벡터는 일련의 숫자로 나타내며, 이 숫자는 해당 데이터의 특징을 수학적으로 나타낸다.
✅ 벡터 데이터베이스(Vector Database) : 벡터 임베딩을 저장하고, 사용자가 입력한 쿼리와 가장 유사한 벡터 데이터를 찾는다.
✅ 쿼리 결과(Query Result) : 사용자가 입력한 쿼리와 유사한 벡터 데이터를 찾아 결과로 반환한다. 이 과정에서 벡터 간 유사성을 계산하여 가장 적합한 데이터를 찾아내는 것이 핵심이다. |
|
|
이 지표들을 적용한 결과를 살펴봄으로써, 소프트웨어 개발팀이 얼마나 효율적이고 안정적으로 일하고 있는지를 알 수 있는 거죠. 현재 전 세계 많은 조직이 이 지표를 통해 개발 및 운영 프로세스를 최적화하고 있답니다. |
|
|
자꾸 벡터, 벡터 하는데 벡터란 뭘까요? 사실 우린 벡터의 기본 개념을 이미 중학교 시절 배웠다는 사실! 하지만 ‘이런 걸 배웠나?😎’ 싶은 수포자도 무릎을 탁 칠만큼 쉽게 소환해 볼게요. 벡터는 방향과 크기를 함께 나타내는 개념이에요. 2차원이나 3차원 공간의 한 점에서→다른 점까지 이동할 때, 그 방향과 거리를 벡터로 표현할 수 있어요. ‘어디로, 얼마나 갈지’를 나타내는 화살표 같은 거예요. 이 화살표는 방향과 크기라는 두 가지 중요한 정보를 제공하죠.
|
|
|
예를 들어볼까요? 만약 님이 동쪽으로 3km를 걷는다면, 여기서 방향은 동쪽, 크기는 3km죠. 이게 바로 벡터의 핵심 개념이에요. 또한 날씨 예보에서 바람의 방향과 세기를 나타내는 데도 벡터가 사용되고, 게임에서 캐릭터가 이동하는 방향과 속도도 벡터로 표현되죠. (참 쉽죠잉😘)
|
|
|
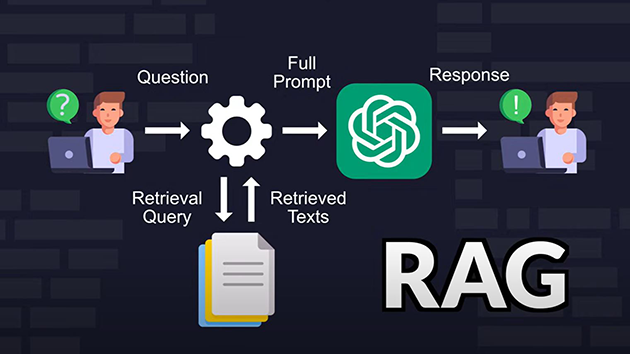
이쯤에서 한 가지 의문이 들 수 있어요. "그런데 왜 벡터DB가 근래 주목받고 있는 거지?"라는 거죠.😮 이에 대한 답은 바로 RAG(Retrieval Augmented Generation) 기술과 관련이 있어요. RAG 기술은 최근 자연어 처리 분야에서 매우 중요한 기술 중 하나로, 검색과 생성을 결합한 모델이에요. 외부 지식을 활용하여 입력값의 컨텍스트를 확장하고, 이를 바탕으로 보다 정확하고 풍부한 결과를 생성해요. 이런 특성 덕분에 RAG는 학습된 패턴 이외의 정보도 잘 처리할 수 있어, 기존 모델과는 확연히 차별화되는데요. 딥러닝 모델을 사용해 문장을 벡터로 변환하고, 이 벡터들 간의 유사도를 측정함으로써 질문과 답변 간의 연관성을 파악하는데 사용되요. |
|
|
즉, RAG 기술을 이용하면 사용자의 의도를 세밀하게 분석해, 이에 따른 정보를 제공할 수 있어요.📝 하지만 이런 기술을 활용하기 위해서는 대량의 데이터가 필요한 것은 물론, 이를 효율적으로 관리하고 검색할 수 있는 도구가 있어야 해요. 이때 사용되는 것 중 하나가 바로 벡터DB인 거죠. 벡터DB는 RAG 기술을 지원하기 위한 핵심적인 도구로, 다차원 벡터 공간을 사용해 방대한 데이터를 효율적으로 관리하고 검색해요. 이처럼 상호보완적인 두 기술은 함께 사용할 경우 더욱 정확하고 신속한 검색 결과를 제공할 수 있답니다. |
|
|
그럼 벡터 데이터베이스는 어떤 기능들을 제공할까요? 강력한 파워 4개를 소개할게요. |
|
|
1) 벡터화(Embedding)
이미지나 영상 같은 비정형 데이터를 숫자(벡터)로 변환해 저장하는데요. 이 과정에서 임베딩 기술이 사용돼요. 이는 복잡한 데이터를 더 간단하게 압축하는 방식으로, 큰 파일을 압축해서 작게 만들되, 중요한 정보는 그대로 유지하죠.
|
|
|
2) 유사성 검색(Similarity Search)
유사한 데이터를 빠르게 찾는 기능이 강력해요. 특정 벡터와 가장 비슷한 벡터를 찾아내는 방식으로, 같은 의미나 맥락을 가진 데이터를 쉽게 검색할 수 있어요. 이를 위해 ANN(Approximate Nearest Neighbors) 알고리즘이 주로 사용되는데, 이는 대규모 데이터 속에서 가장 비슷한 데이터를 빠르게 찾아주죠.
|
|
|
3) 인덱싱 기법
대규모 데이터를 효과적으로 검색하려면 인덱싱 기법이 필요해요. 벡터DB에서는 LSH, HNSW, IVF 등의 기법이 사용되는데, 각각 데이터의 특성에 맞춰 사용돼요.
· LSH(Locality Sensitive Hashing) : 유사한 데이터를 같은 그룹으로 묶어 검색을 빠르게 하는 방법
· HNSW(Hierarchical Navigable Small World graphs) : 벡터 간 관계를 그래프로 구성해 빠르게 유사한 데이터를 찾는 기법
· IVF(Inverted File Index) : 데이터를 클러스터로 나누어 검색 속도와 메모리 효율성을 높이는 기법
|
|
|
4) 확장성 및 분산 처리
대규모 데이터를 병렬로 처리할 수 있어, 수십억 개의 벡터도 빠르게 검색할 수 있어요. 이를 통해 AI와 빅데이터 분석에 필요한 속도와 처리 능력을 제공해요.
|
|
|
최근 벡터DB 기술이 주목받으면서 (요아정도 울고 갈😋) 다양한 벡터 데이터베이스 솔루션들이 나오고 있어요. |
|
|
💡 Vector Libraries
주로 소규모 프로젝트에서 벡터 검색과 유사성 검색을 수행하는 데 사용돼요. 다양한 애플리케이션에 쉽게 통합할 수 있다는 것이 장점이죠. |
|
|
💡 Vector-only Databases
벡터 데이터의 저장과 검색에 특화되어 있으며, 주로 대규모 벡터 데이터를 빠르고 효율적으로 처리하는 데 최적화되어 있어요.
|
|
|
- Pinecone: Pinecone : 벡터 데이터를 저장하고 관리하는 완전 관리형 데이터베이스 솔루션. 특히 대규모 벡터 데이터를 실시간으로 처리할 수 있으며, 자동 스케일링 기능을 통해 사용자의 요구에 따라 성능을 조정할 수 있음. 덕분에, 데이터양이 커져도 안정적으로 데이터를 처리하고 검색할 수 있음.
- Weaviate : 오픈소스 벡터 데이터베이스 솔루션으로, 자연어 처리 기능이 내장되어 있어 텍스트, 이미지, 비디오 같은 다양한 비정형 데이터를 저장하고 검색할 수 있음. GraphQL 인터페이스와 쉽게 통합할 수 있어 개발자들에게 친숙한 환경을 제공.
- Milvus: Milvus : AI 애플리케이션에 최적화된 고성능 벡터 데이터베이스 솔루션. 다양한 인덱싱 기법과 유사성 검색 알고리즘을 제공하며, 대규모 데이터를 빠르게 처리할 수 있음. 특히 확장성이 뛰어나며, 대용량 데이터에서도 검색 속도를 유지할 수 있음. |
|
|
💡 Enterprise DBs with Vectors
기존의 관계형 데이터베이스나 NoSQL 데이터베이스에 벡터 검색 기능을 추가한 솔루션들이에요. 이를 통해 벡터 데이터와 구조화된 데이터를 동시에 처리할 수 있는데요, 텍스트나 숫자 같은 기존의 정형 데이터와 벡터화된 데이터(이미지, 비디오 등)를 함께 활용할 수 있는 시스템이에요.
|
|
|
- SingleStore : 고성능의 분산 데이터베이스로, 관계형 데이터베이스와 벡터 검색 기능을 모두 제공. 대규모 데이터를 실시간으로 처리할 수 있으며, 벡터 데이터와 구조화된 데이터를 동시에 관리할 수 있어 하이브리드 데이터베이스로 널리 사용됨.
- ElasticSearch : 기존 강력한 텍스트 검색 기능으로 유명하지만, 최근에는 벡터 검색 기능도 추가됨. 단순한 키워드 검색을 넘어서 의미 기반으로 유사한 데이터를 검색할 수 있게 됨. 텍스트와 벡터 데이터를 동시에 다룰 수 있어 대규모 텍스트 데이터와 비정형 데이터를 통합 관리 가능.
- PostgreSQL with pgvector : 인기 있는 오픈소스 관계형 데이터베이스 솔루션으로, pgvector 확장을 통해 벡터 데이터 검색 기능을 추가할 수 있음. 이를 통해 기존의 구조화된 데이터와 벡터 데이터를 통합 관리할 수 있으며, 복잡한 쿼리와 함께 벡터 유사성 검색을 실행할 수 있는 유연성을 제공. |
|
|
어쩌면 성동수 프로만 기억할지 모를😂 영화 ‘제5원소(‘97년 개봉)’에선 자동차들이 하늘을 날아다니는데요. 조만간 그런 미래가 올 거라고 기대했지만 여전히 영화적인 현실은 도래하지 않았죠. 거대한 사회적 변화는 좀 기다려야겠지만, 우리도 모르게 일상 속에서 작지만 거대한 변화는 벌써 일어나고 있어요. 바로 AI 기술 발전으로 말이죠. |
|
|
"벡터 검색보다 더 파워풀한 검색이 나오면,
아마 그건 천터 검색? >,.< |
|
|
날아다니는 택시🚕는 언제 탈지 모르겠지만, 닥터 스트레인지의 목에 걸린 타임스톤은 작은 키보드 속에서 이미 조금씩 돌아가고 있다는 사실! 물론 스트레인지는 엄청난 에너지를 쏟아내며 타노스를 무찌르기 위한 1,400만 가지 시나리오를 체험하지만, 우린 벡터DB 라는 혁신적인 기술 덕분에 수많은 정보 속 우리가 원하는 정답을 더 정확하게 찾아낼 수 있게 됐어요. 다음 11월 호엔 어벤져스 이상급의 더 흥미로운 혁신 얘기로 찾아올게요!
|
|
|
📌오늘의 이야기 간단 정리!
· AI 시대의 데이터 관리와 검색을 혁신하는 '벡터DB'는 대량의 비정형 데이터를 효율적으로 처리하여 우리가 원하는 정보를 더 빠르고 정확하게 찾도록 돕는다. |
|
|
· 혁신적인 기술 덕분에 검색의 한계를 넘어선 새로운 정보 활용의 시대가 열리고 있으며, 우리의 일상과 의사결정을 더욱 스마트하게 변화시키고 있다. |
|
|
이번 호는 어떠셨나요? 슫몰토크 피드백을 통해, 결론에 대한 간략한 정리가 있었으면 좋겠다는 의견을 주셔서 본문 마지막 부분에 반영해 보았는데..😘 혹시 또 슫스레터가 좀 더 디벨롭 되었으면 하는 부분이나 저희 3명의 멘토들에게 하고 싶은 이야기가 있다면 아주 사소한 거라도 좋으니 편하게 피드백 남겨주세요.😉 님의 소중한 시간을 내어주셔서 피드백 남겨주신 분들께는 감사의 마음을 담아 추첨을 통해 선물도 드려요!
🎁 선물 : [스타벅스] 우정의 맹세 세트 (10명)
📌 이벤트 기간 : 10/21(월) ~ 10/27(일)
📌 당첨자 발표 : 10/30(수)
|
|
|
오늘의 슫스레터는 여기까지입니다.
슫스레터를 함께 읽고 싶은 친구가 떠올랐나요?
그렇다면 아래 구독 신청 링크를 공유해 주세요!
지난 뉴스레터가 궁금하다면?
|
|
|
삼성SDS 소셜미디어itnews@samsungsdsletter.com서울 송파구 올림픽로35길 125 삼성SDS Campus 02-6155-3114수신거부 Unsubscribe |
|
|
|